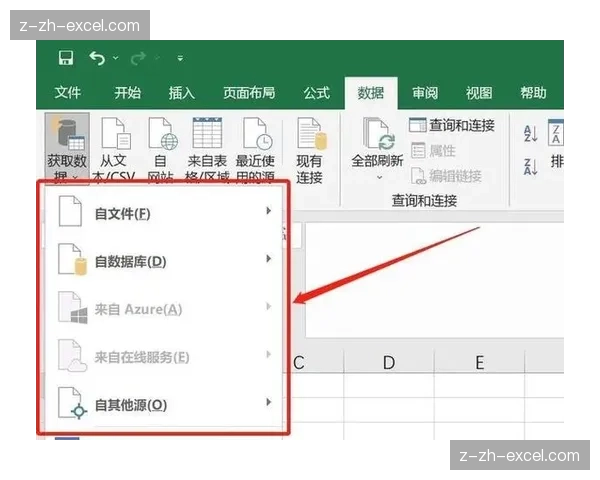
йҰ–е…ҲпјҢжҲ‘们йңҖиҰҒзҗҶи§ЈExcelеңЁеҜје…Ҙж•°жҚ®ж—¶зҡ„еҶ…йғЁеӨ„зҗҶжңәеҲ¶гҖӮеҪ“з”ЁжҲ·йҖүжӢ©вҖңж•°жҚ®вҖқйҖүйЎ№еҚЎдёӯзҡ„вҖңиҺ·еҸ–ж•°жҚ®вҖқеҠҹиғҪж—¶пјҢExcelе®һйҷ…дёҠдјҡйҖҡиҝҮODBCжҲ–OLEDBй©ұеҠЁзЁӢеәҸдёҺеӨ–йғЁж•°жҚ®жәҗе»әз«ӢиҝһжҺҘгҖӮиҝҷдёҖиҝҮзЁӢ并йқһз®ҖеҚ•ең°е°Ҷж•°жҚ®жәҗдёӯзҡ„еӯ—ж®өзӣҙжҺҘжҳ е°„еҲ°Excelе·ҘдҪңиЎЁдёӯпјҢиҖҢжҳҜйҖҡиҝҮдёҖдёӘдёӯй—ҙжӯҘйӘӨвҖ”вҖ”вҖңж•°жҚ®йҖҸи§ҶиЎЁвҖқжҲ–вҖңжҹҘиҜўзј–иҫ‘еҷЁвҖқжқҘеӨ„зҗҶж•°жҚ®гҖӮеңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢExcelдјҡе°ҶеӨ–йғЁж•°жҚ®жәҗдёӯзҡ„еӯ—ж®өйҮҚж–°е‘ҪеҗҚдёәвҖңF1вҖқгҖҒвҖңF2вҖқзӯүй»ҳи®ӨеҗҚз§°пјҢд»Ҙдҫҝз”ЁжҲ·еңЁеҗҺз»ӯзҡ„зј–иҫ‘дёӯиҝӣиЎҢиҮӘе®ҡд№үе‘ҪеҗҚгҖӮиҝҷдёҖжңәеҲ¶зҡ„и®ҫи®ЎеҲқиЎ·жҳҜдёәдәҶз®ҖеҢ–ж•°жҚ®еҜје…Ҙзҡ„еҲқе§ӢжӯҘйӘӨпјҢйҒҝе…Қз”ЁжҲ·еңЁеҜје…ҘиҝҮзЁӢдёӯеӣ еӯ—ж®өеҗҚеҢ…еҗ«зү№ж®Ҡеӯ—з¬ҰжҲ–дёҺExcelеҶ…зҪ®еҠҹиғҪеҶІзӘҒиҖҢеҜјиҮҙзҡ„й”ҷиҜҜгҖӮ然иҖҢпјҢиҝҷдёҖи®ҫи®ЎеҚҙеёҰжқҘдәҶдёҖдёӘзңӢдјјз®ҖеҚ•еҚҙеҪұе“Қж·ұиҝңзҡ„й—®йўҳпјҡеҜје…ҘеҗҺзҡ„еӯ—ж®өеҗҚеҸҳеҫ—дёҚзӣҙи§ӮпјҢз”ҡиҮіе®Ңе…ЁеӨұеҺ»дәҶеҺҹе§Ӣеҗ«д№үгҖӮ
жӣҙж·ұе…Ҙең°иҜҙпјҢExcelеңЁеҜје…Ҙж•°жҚ®ж—¶зҡ„еӯ—ж®өжҳ е°„йҖ»иҫ‘дёҺдј з»ҹзҡ„ж•°жҚ®еә“иҝһжҺҘж–№ејҸжңүзқҖжң¬иҙЁзҡ„дёҚеҗҢгҖӮеңЁдј з»ҹзҡ„ж•°жҚ®еә“иҝһжҺҘдёӯпјҢж•°жҚ®еә“з®ЎзҗҶзі»з»ҹпјҲDBMSпјүдјҡж №жҚ®йў„е®ҡд№үзҡ„жҳ е°„е…ізі»е°Ҷж•°жҚ®еә“иЎЁдёӯзҡ„еӯ—ж®өдёҺеә”з”ЁзЁӢеәҸдёӯзҡ„еҸҳйҮҸдёҖдёҖеҜ№еә”гҖӮ然иҖҢпјҢExcelдҪңдёәдёҖж¬ҫз”өеӯҗиЎЁж јиҪҜ件пјҢ并дёҚе…·еӨҮиҝҷз§Қйў„е®ҡд№үзҡ„жҳ е°„жңәеҲ¶гҖӮзӣёеҸҚпјҢExcelеңЁеҜје…Ҙж•°жҚ®ж—¶йҮҮз”ЁдәҶдёҖз§ҚжӣҙдёәзҒөжҙ»дҪҶзӣёеҜ№дёҚйҖҸжҳҺзҡ„ж–№ејҸгҖӮе…·дҪ“жқҘиҜҙпјҢExcelдјҡе°ҶеӨ–йғЁж•°жҚ®жәҗдёӯзҡ„жҜҸдёҖеҲ—и§ҶдёәдёҖдёӘзӢ¬з«Ӣзҡ„ж•°жҚ®жөҒпјҢ然еҗҺйҖҡиҝҮдёҖдёӘдёҙж—¶зҡ„ж•°жҚ®иЎЁжқҘеӯҳеӮЁиҝҷдәӣж•°жҚ®гҖӮеңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢExcel并дёҚдјҡдҝқз•ҷеҺҹе§Ӣеӯ—ж®өеҗҚпјҢиҖҢжҳҜдёәжҜҸдёҖеҲ—з”ҹжҲҗдёҖдёӘйҖҡз”Ёзҡ„ж ҮиҜҶз¬ҰпјҢеҰӮвҖңF1вҖқгҖҒвҖңF2вҖқзӯүгҖӮиҝҷдёҖеҒҡжі•иҷҪ然еңЁжҠҖжңҜдёҠз®ҖеҢ–дәҶж•°жҚ®еҜје…Ҙзҡ„жөҒзЁӢпјҢдҪҶеҚҙзүәзүІдәҶж•°жҚ®зҡ„еҸҜиҜ»жҖ§е’ҢеҸҜз»ҙжҠӨжҖ§гҖӮ
йҷӨдәҶжҠҖжңҜжңәеҲ¶зҡ„йҷҗеҲ¶пјҢиҝҷдёҖзҺ°иұЎиҝҳдёҺExcelзҡ„ж•°жҚ®еӨ„зҗҶжһ¶жһ„еҜҶеҲҮзӣёе…ігҖӮExcelзҡ„ж•°жҚ®еӨ„зҗҶжһ¶жһ„дё»иҰҒеҹәдәҺCOMпјҲComponent Object Modelпјүе’ҢOLEпјҲObject Linking and EmbeddingпјүжҠҖжңҜпјҢиҝҷдәӣжҠҖжңҜеңЁж•°жҚ®еҜје…ҘиҝҮзЁӢдёӯжү®жј”зқҖе…ій”®и§’иүІгҖӮCOMе’ҢOLEжҠҖжңҜе…Ғи®ёExcelдёҺе…¶д»–еә”з”ЁзЁӢеәҸиҝӣиЎҢж•°жҚ®дәӨжҚўпјҢдҪҶеҗҢж—¶д№ҹеј•е…ҘдәҶж•°жҚ®иҪ¬жҚўе’Ңеӯ—ж®өжҳ е°„зҡ„еӨҚжқӮжҖ§гҖӮеҪ“ExcelеҜје…Ҙж•°жҚ®ж—¶пјҢе®ғе®һйҷ…дёҠжҳҜеңЁиҝӣиЎҢдёҖз§ҚвҖңдёӯй—ҙиҪ¬жҚўвҖқпјҢеҚіе°ҶеӨ–йғЁж•°жҚ®жәҗдёӯзҡ„ж•°жҚ®ж јејҸиҪ¬жҚўдёәExcelеҶ…йғЁзҡ„ж•°жҚ®ж јејҸгҖӮеңЁиҝҷдёӘиҝҮзЁӢдёӯпјҢеӯ—ж®өеҗҚзҡ„иҪ¬жҚўжҳҜдёҖдёӘдёҚеҸҜйҒҝе…Қзҡ„жӯҘйӘӨгҖӮз”ұдәҺExcelжІЎжңүеҶ…зҪ®зҡ„еӯ—ж®өжҳ 射规еҲҷпјҢеӣ жӯӨе®ғеҸӘиғҪдҫқиө–дәҺеӨ–йғЁж•°жҚ®жәҗзҡ„е…ғж•°жҚ®пјҲmetadataпјүжқҘзЎ®е®ҡеӯ—ж®өеҗҚгҖӮеҰӮжһңеӨ–йғЁж•°жҚ®жәҗзҡ„е…ғж•°жҚ®дёҚе®Ңж•ҙжҲ–дёҚдёҖиҮҙпјҢExcelе°ұдјҡз”ҹжҲҗй»ҳи®Өзҡ„еӯ—ж®өеҗҚпјҢеҰӮвҖңF1вҖқгҖҒвҖңF2вҖқзӯүгҖӮ

жӯӨеӨ–пјҢиҝҷдёҖзҺ°иұЎиҝҳеҸҚжҳ дәҶExcelеңЁж•°жҚ®еҜје…ҘеҠҹиғҪдёҠзҡ„и®ҫи®ЎеҸ–еҗ‘гҖӮExcelдҪңдёәдёҖдёӘйҖҡз”Ёзҡ„з”өеӯҗиЎЁж јиҪҜ件пјҢе…¶и®ҫи®ЎеҲқиЎ·жҳҜдёәдәҶеӨ„зҗҶз»“жһ„еҢ–ж•°жҚ®пјҢиҖҢйқһдё“й—Ёзҡ„ж•°жҚ®еҜје…Ҙе·Ҙе…·гҖӮеӣ жӯӨпјҢеңЁеҜје…Ҙж•°жҚ®ж—¶пјҢExcelжӣҙжіЁйҮҚзҡ„жҳҜж•°жҚ®зҡ„е®Ңж•ҙжҖ§е’ҢеҸҜз”ЁжҖ§пјҢиҖҢйқһж•°жҚ®зҡ„еҸҜиҜ»жҖ§е’Ңжҳ“з”ЁжҖ§гҖӮиҝҷдёҖи®ҫи®ЎзҗҶеҝөиҷҪ然еңЁдёҖе®ҡзЁӢеәҰдёҠжҸҗй«ҳдәҶж•°жҚ®еҜје…Ҙзҡ„ж•ҲзҺҮпјҢдҪҶд№ҹеёҰжқҘдәҶдёҖдәӣеүҜдҪңз”ЁпјҢжҜ”еҰӮеӯ—ж®өеҗҚзҡ„дёўеӨұжҲ–з®Җexcel表格下载еҢ–гҖӮеҜ№дәҺйӮЈдәӣйңҖиҰҒйў‘з№ҒеҜје…Ҙж•°жҚ®зҡ„з”ЁжҲ·жқҘиҜҙпјҢиҝҷдёҖй—®йўҳе°ӨдёәжҳҺжҳҫгҖӮ他们еҫҖеҫҖйңҖиҰҒеңЁеҜје…ҘеҗҺжүӢеҠЁдҝ®ж”№еӯ—ж®өеҗҚпјҢиҝҷдёҚд»…еўһеҠ дәҶе·ҘдҪңйҮҸпјҢиҝҳеҸҜиғҪеҜјиҮҙж•°жҚ®зҡ„дёҖиҮҙжҖ§е’ҢеҮҶзЎ®жҖ§еҸ—еҲ°еҪұе“ҚгҖӮ
ExcelеҜје…Ҙж•°жҚ®зҡ„и§ЈеҶіж–№жЎҲдёҺдјҳеҢ–е»әи®®
йқўеҜ№иҝҷдёҖжҠҖжңҜй—®йўҳпјҢз”ЁжҲ·йңҖиҰҒзҡ„дёҚд»…д»…жҳҜеҜ№е…¶еҺҹеӣ зҡ„зҗҶи§ЈпјҢжӣҙйҮҚиҰҒзҡ„жҳҜжүҫеҲ°жңүж•Ҳзҡ„и§ЈеҶіж–№жЎҲгҖӮе№ёиҝҗзҡ„жҳҜпјҢExcelжҸҗдҫӣдәҶдёҖдәӣеҶ…зҪ®зҡ„еҠҹиғҪе’Ң第дёүж–№е·Ҙе…·пјҢеҸҜд»Ҙеё®еҠ©з”ЁжҲ·и§ЈеҶіиҝҷдёҖй—®йўҳгҖӮйҰ–е…ҲпјҢExcelзҡ„вҖңжҹҘиҜўзј–иҫ‘еҷЁвҖқеҠҹиғҪжҳҜдёҖдёӘејәеӨ§зҡ„е·Ҙе…·пјҢе®ғе…Ғи®ёз”ЁжҲ·еңЁеҜје…Ҙж•°жҚ®зҡ„иҝҮзЁӢдёӯеҜ№еӯ—ж®өиҝӣиЎҢиҮӘе®ҡд№үе‘ҪеҗҚгҖӮеҪ“з”ЁжҲ·йҖҡиҝҮвҖңиҺ·еҸ–ж•°жҚ®вҖқеҠҹиғҪеҜје…Ҙж•°жҚ®еҗҺпјҢеҸҜд»Ҙиҝӣе…ҘвҖңжҹҘиҜўзј–иҫ‘еҷЁвҖқз•ҢйқўпјҢеңЁиҝҷйҮҢпјҢз”ЁжҲ·еҸҜд»ҘзңӢеҲ°жҜҸдёӘеӯ—ж®өзҡ„еҺҹе§ӢеҗҚз§°е’Ңзұ»еһӢгҖӮ然еҗҺпјҢз”ЁжҲ·еҸҜд»ҘеҸій”®зӮ№еҮ»еӯ—ж®өеҗҚпјҢйҖүжӢ©вҖңйҮҚе‘ҪеҗҚвҖқйҖүйЎ№пјҢе°Ҷеӯ—ж®өеҗҚжӣҙж”№дёәжңүж„Ҹд№үзҡ„еҗҚз§°гҖӮиҝҷдёҖиҝҮзЁӢдёҚд»…з®ҖеҚ•жҳ“иЎҢпјҢиҖҢдё”дёҚдјҡеҪұе“Қж•°жҚ®зҡ„з»“жһ„е’Ңе®Ңж•ҙжҖ§гҖӮ
йҷӨдәҶдҪҝз”ЁвҖңжҹҘиҜўзј–иҫ‘еҷЁвҖқеҠҹиғҪпјҢз”ЁжҲ·иҝҳеҸҜд»ҘйҖҡиҝҮеҲӣе»әиҮӘе®ҡд№үзҡ„Power QueryжҹҘиҜўжқҘдјҳеҢ–ж•°жҚ®еҜје…ҘиҝҮзЁӢгҖӮPower QueryжҳҜExcelдёӯдёҖдёӘејәеӨ§зҡ„ж•°жҚ®еӨ„зҗҶе·Ҙе…·пјҢе®ғе…Ғи®ёз”ЁжҲ·зј–еҶҷиҮӘе®ҡд№үзҡ„MиҜӯиЁҖд»Јз ҒжқҘеӨ„зҗҶж•°жҚ®гҖӮйҖҡиҝҮзј–еҶҷMиҜӯиЁҖд»Јз ҒпјҢз”ЁжҲ·еҸҜд»ҘеңЁеҜје…Ҙж•°жҚ®зҡ„иҝҮзЁӢдёӯзӣҙжҺҘдҝ®ж”№еӯ—ж®өеҗҚпјҢд»ҺиҖҢйҒҝе…ҚдәҶй»ҳи®Өеӯ—ж®өеҗҚзҡ„еҮәзҺ°гҖӮдҫӢеҰӮпјҢз”ЁжҲ·еҸҜд»ҘйҖҡиҝҮд»ҘдёӢд»Јз Ғе°ҶеҜје…Ҙзҡ„еӯ—ж®өеҗҚд»ҺвҖңF1вҖқжӣҙж”№дёәвҖңCustomerIDвҖқпјҡ
let Source = Excel.IO.Open("C:\Data\SampleData.xlsx"), #"Changed Type" = Table.TransformColumnTypes(Source,{{"F1", type text}}), Custom_Field = Table.AddColumn(#"Changed Type", "CustomerID", each [F1], type text), #"Removed Columns" = Table.RemoveColumns(Custom_Field,{"F1"}) in #"Removed Columns"
иҝҷдёҖд»Јз ҒзӨәдҫӢеұ•зӨәдәҶеҰӮдҪ•йҖҡиҝҮMиҜӯиЁҖд»Јз Ғе°ҶеҜје…Ҙзҡ„еӯ—ж®өеҗҚвҖңF1вҖқжӣҙж”№дёәвҖңCustomerIDвҖқпјҢ并еҲ йҷӨеҺҹе§Ӣеӯ—ж®өгҖӮиҷҪ然编еҶҷMиҜӯиЁҖд»Јз ҒйңҖиҰҒдёҖе®ҡзҡ„жҠҖжңҜиғҢжҷҜпјҢдҪҶе®ғжҸҗдҫӣдәҶжһҒеӨ§зҡ„зҒөжҙ»жҖ§е’ҢжҺ§еҲ¶еҠӣпјҢйҖӮеҗҲйӮЈдәӣйңҖиҰҒеӨ„зҗҶеӨҚжқӮж•°жҚ®еҜје…ҘеңәжҷҜзҡ„з”ЁжҲ·гҖӮ
еҜ№дәҺйӮЈдәӣдёҚзҶҹжӮүPower QueryжҲ–MиҜӯиЁҖд»Јз Ғзҡ„з”ЁжҲ·пјҢExcelиҝҳжҸҗдҫӣдәҶеҸҰдёҖз§Қжӣҙдёәз®ҖеҚ•зҡ„и§ЈеҶіж–№жЎҲпјҡдҪҝз”ЁвҖңж•°жҚ®йҖҸи§ҶиЎЁвҖқеҠҹиғҪгҖӮеҪ“з”ЁжҲ·еҜје…Ҙж•°жҚ®еҗҺпјҢеҸҜд»Ҙе°Ҷж•°жҚ®иҪ¬жҚўдёәж•°жҚ®йҖҸи§ҶиЎЁпјҢ然еҗҺеңЁж•°жҚ®йҖҸи§ҶиЎЁдёӯиҮӘе®ҡд№үеӯ—ж®өеҗҚгҖӮиҷҪ然иҝҷдёҖж–№жі•еңЁдёҖе®ҡзЁӢеәҰдёҠеўһеҠ дәҶж•°жҚ®еӨ„зҗҶзҡ„еӨҚжқӮжҖ§пјҢдҪҶе®ғдёәз”ЁжҲ·жҸҗдҫӣдәҶжӣҙеӨҡзҡ„зҒөжҙ»жҖ§е’ҢжҺ§еҲ¶еҠӣгҖӮжӯӨеӨ–пјҢз”ЁжҲ·иҝҳеҸҜд»ҘйҖҡиҝҮExcelзҡ„вҖңж•°жҚ®иҝһжҺҘвҖқеҠҹиғҪеҲӣе»әжҢҒд№…еҢ–зҡ„ж•°жҚ®иҝһжҺҘпјҢиҝҷдёҚд»…еҸҜд»ҘйҒҝе…ҚжҜҸж¬ЎеҜје…Ҙж•°жҚ®ж—¶йғҪиҰҒйҮҚж–°жҳ е°„еӯ—ж®өеҗҚпјҢиҝҳеҸҜд»ҘжҸҗй«ҳж•°жҚ®еҜје…Ҙзҡ„ж•ҲзҺҮе’ҢдёҖиҮҙжҖ§гҖӮ
йҷӨдәҶдёҠиҝ°и§ЈеҶіж–№жЎҲпјҢз”ЁжҲ·иҝҳеҸҜд»ҘиҖғиҷ‘дҪҝ用第дёүж–№ж•°жҚ®еҜје…Ҙе·Ҙе…·жқҘдјҳеҢ–ж•°жҚ®еҜје…ҘиҝҮзЁӢгҖӮиҝҷдәӣе·Ҙе…·йҖҡеёёжҸҗдҫӣжӣҙдёәеҸӢеҘҪзҡ„з”ЁжҲ·з•Ңйқўе’ҢжӣҙејәеӨ§зҡ„еҠҹиғҪпјҢеҸҜд»Ҙеё®еҠ©з”ЁжҲ·жӣҙиҪ»жқҫең°и§ЈеҶіеӯ—ж®өеҗҚжҳ е°„й—®йўҳгҖӮдҫӢеҰӮпјҢдёҖдәӣе·Ҙе…·е…Ғи®ёз”ЁжҲ·еңЁеҜје…Ҙж•°жҚ®д№ӢеүҚйў„е®ҡд№үеӯ—ж®өжҳ 射规еҲҷпјҢд»ҺиҖҢйҒҝе…ҚдәҶExcelй»ҳи®Өеӯ—ж®өеҗҚзҡ„еҮәзҺ°гҖӮжӯӨеӨ–пјҢдёҖдәӣе·Ҙе…·иҝҳжҸҗдҫӣдәҶж•°жҚ®жё…жҙ—е’ҢиҪ¬жҚўеҠҹиғҪпјҢеҸҜд»Ҙеё®еҠ©з”ЁжҲ·еңЁеҜје…Ҙж•°жҚ®зҡ„иҝҮзЁӢдёӯиҝӣиЎҢж•°жҚ®йӘҢиҜҒе’Ңй”ҷиҜҜдҝ®еӨҚгҖӮиҷҪ然иҝҷдәӣе·Ҙе…·еҸҜиғҪйңҖиҰҒдёҖе®ҡзҡ„еӯҰд№ жҲҗжң¬пјҢдҪҶе®ғ们йҖҡеёёиғҪеӨҹжҳҫи‘—жҸҗй«ҳж•°жҚ®еҜје…Ҙзҡ„ж•ҲзҺҮе’ҢеҮҶзЎ®жҖ§гҖӮ
ж•°жҚ®еҜје…Ҙзҡ„жңӘжқҘеҸ‘еұ•и¶ӢеҠҝдёҺиЎҢдёҡеҪұе“Қ
йҡҸзқҖж•°жҚ®й©ұеҠЁеҶізӯ–зҡ„жҷ®еҸҠпјҢж•°жҚ®еҜје…Ҙе’ҢеӨ„зҗҶзҡ„ж•ҲзҺҮе’ҢеҮҶзЎ®жҖ§еҸҳеҫ—и¶ҠжқҘи¶ҠйҮҚиҰҒгҖӮиҝҷдёҖзҺ°иұЎвҖ”вҖ”еҚіеҜје…Ҙж•°жҚ®еҗҺеӯ—ж®өеҗҚеҸҳдёәвҖңF1вҖқгҖҒвҖңF2вҖқзӯүй»ҳи®ӨеҗҚз§°вҖ”вҖ”иҷҪ然еңЁжҠҖжңҜдёҠзңӢдјјз®ҖеҚ•пјҢеҚҙеҸҚжҳ дәҶжӣҙж·ұеұӮж¬Ўзҡ„иЎҢдёҡи¶ӢеҠҝе’ҢжҢ‘жҲҳгҖӮйҰ–е…ҲпјҢиҝҷдёҖй—®йўҳзҡ„жҷ®йҒҚеӯҳеңЁиЎЁжҳҺпјҢеҪ“еүҚзҡ„ж•°жҚ®еҜје…Ҙе·Ҙе…·еңЁз”ЁжҲ·дҪ“йӘҢе’ҢеҠҹиғҪи®ҫи®ЎдёҠиҝҳжңүеҫҲеӨ§зҡ„ж”№иҝӣз©әй—ҙгҖӮз”ЁжҲ·еңЁеҜје…Ҙж•°жҚ®еҗҺйңҖиҰҒиҠұиҙ№йўқеӨ–зҡ„ж—¶й—ҙе’ҢзІҫеҠӣжқҘйҮҚе‘ҪеҗҚеӯ—ж®өпјҢиҝҷдёҚд»…еўһеҠ дәҶе·ҘдҪңиҙҹжӢ…пјҢиҝҳеҸҜиғҪеҜјиҮҙж•°жҚ®зҡ„дёҖиҮҙжҖ§е’ҢеҮҶзЎ®жҖ§еҸ—еҲ°еҪұе“ҚгҖӮеӣ жӯӨпјҢжңӘжқҘзҡ„ж•°жҚ®еҜје…Ҙе·Ҙе…·йңҖиҰҒжӣҙеҠ жіЁйҮҚз”ЁжҲ·дҪ“йӘҢпјҢжҸҗдҫӣжӣҙеҠ жҷәиғҪе’ҢиҮӘеҠЁеҢ–зҡ„еӯ—ж®өжҳ е°„еҠҹиғҪгҖӮ
е…¶ж¬ЎпјҢиҝҷдёҖй—®йўҳд№ҹеҸҚжҳ дәҶж•°жҚ®ж ҮеҮҶеҢ–е’Ңж•°жҚ®иҙЁйҮҸз®ЎзҗҶзҡ„йҮҚиҰҒжҖ§гҖӮеңЁи®ёеӨҡжғ…еҶөдёӢпјҢж•°жҚ®еҜје…ҘеӨұиҙҘжҲ–еӯ—ж®өеҗҚдёўеӨұзҡ„еҺҹеӣ еңЁдәҺж•°жҚ®жәҗжң¬иә«зҡ„дёҚ规иҢғгҖӮдҫӢеҰӮпјҢеҰӮжһңеӨ–йғЁж•°жҚ®жәҗзҡ„еӯ—ж®өеҗҚеҢ…еҗ«зү№ж®Ҡеӯ—з¬ҰжҲ–дҪҝз”ЁдәҶдёҚеҗҢзҡ„зј–з Ғж ҮеҮҶпјҢExcelеңЁеҜје…Ҙж•°жҚ®ж—¶еҸҜиғҪдјҡйҒҮеҲ°й—®йўҳгҖӮеӣ жӯӨпјҢжңӘжқҘзҡ„ж•°жҚ®еҜје…Ҙе·Ҙе…·йңҖиҰҒжӣҙеҘҪең°ж”ҜжҢҒж•°жҚ®ж ҮеҮҶеҢ–е’Ңж•°жҚ®иҙЁйҮҸйӘҢиҜҒпјҢеё®еҠ©з”ЁжҲ·еңЁеҜје…Ҙж•°жҚ®д№ӢеүҚиҜҶеҲ«е’Ңдҝ®еӨҚиҝҷдәӣй—®йўҳгҖӮжӯӨеӨ–пјҢйҡҸзқҖдәәе·ҘжҷәиғҪе’ҢжңәеҷЁеӯҰд№ жҠҖжңҜзҡ„еҸ‘еұ•пјҢжңӘжқҘзҡ„ж•°жҚ®еҜје…Ҙе·Ҙе…·иҝҳеҸҜд»ҘеҲ©з”ЁиҝҷдәӣжҠҖжңҜжқҘиҮӘеҠЁиҜҶеҲ«е’Ңжҳ е°„еӯ—ж®өпјҢиҝӣдёҖжӯҘжҸҗй«ҳж•°жҚ®еҜје…Ҙзҡ„ж•ҲзҺҮе’ҢеҮҶзЎ®жҖ§гҖӮ
еңЁиЎҢдёҡеә”з”ЁеұӮйқўпјҢиҝҷдёҖй—®йўҳеҜ№йӮЈдәӣдҫқиө–ж•°жҚ®еҜје…ҘиҝӣиЎҢж—Ҙеёёе·ҘдҪңзҡ„з”ЁжҲ·дә§з”ҹдәҶж·ұиҝңзҡ„еҪұе“ҚгҖӮдҫӢеҰӮпјҢеңЁйҮ‘иһҚгҖҒеҢ»з–—е’Ңйӣ¶е”®зӯүиЎҢдёҡпјҢж•°жҚ®еҜје…ҘжҳҜдёҡеҠЎжөҒзЁӢдёӯзҡ„е…ій”®зҺҜиҠӮгҖӮеҰӮжһңж•°жҚ®еҜје…ҘиҝҮзЁӢдёӯеӯ—ж®өеҗҚдёўеӨұжҲ–еҸҳеҫ—дёҚзӣҙи§ӮпјҢеҸҜиғҪдјҡеҜјиҮҙеҗҺз»ӯзҡ„ж•°жҚ®еҲҶжһҗе’ҢеҶізӯ–еҮәзҺ°еҒҸе·®гҖӮеӣ жӯӨпјҢдјҒдёҡйңҖиҰҒеңЁж•°жҚ®еҜје…ҘжөҒзЁӢдёӯеј•е…ҘжӣҙеӨҡзҡ„иҮӘеҠЁеҢ–е’Ңж ҮеҮҶеҢ–жҺӘж–ҪпјҢдҫӢеҰӮйҖҡиҝҮзј–еҶҷи„ҡжң¬жҲ–дҪҝз”ЁиҮӘеҠЁеҢ–е·Ҙе…·жқҘз®ЎзҗҶж•°жҚ®еҜје…ҘиҝҮзЁӢгҖӮжӯӨеӨ–пјҢдјҒдёҡиҝҳйңҖиҰҒеҠ ејәеҜ№е‘ҳе·Ҙзҡ„ж•°жҚ®еӨ„зҗҶжҠҖиғҪзҡ„еҹ№и®ӯпјҢзЎ®дҝқ他们иғҪеӨҹзҶҹз»ғдҪҝз”ЁExcelжҲ–е…¶д»–ж•°жҚ®еҜје…Ҙе·Ҙе…·пјҢ并зҗҶи§Јж•°жҚ®еҜје…ҘиҝҮзЁӢдёӯеҸҜиғҪеҮәзҺ°зҡ„й—®йўҳе’Ңи§ЈеҶіж–№жЎҲгҖӮ
жңҖеҗҺпјҢиҝҷдёҖй—®йўҳд№ҹжҸҗйҶ’жҲ‘们пјҢж•°жҚ®еҜје…ҘдёҚд»…д»…жҳҜжҠҖжңҜй—®йўҳпјҢжӣҙжҳҜдёҖдёӘж¶үеҸҠжөҒзЁӢи®ҫи®ЎгҖҒз”ЁжҲ·ж•ҷиӮІе’Ңе·Ҙе…·ејҖеҸ‘зҡ„з»јеҗҲжҖ§й—®йўҳгҖӮжңӘжқҘзҡ„ж•°жҚ®еҜје…Ҙе·Ҙе…·йңҖиҰҒеңЁжҠҖжңҜеҠҹиғҪе’Ңз”ЁжҲ·дҪ“йӘҢд№Ӣй—ҙжүҫеҲ°жӣҙеҘҪзҡ„е№іиЎЎпјҢдёәз”ЁжҲ·жҸҗдҫӣжӣҙеҠ жҷәиғҪгҖҒй«ҳж•Ҳе’Ңжҳ“з”Ёзҡ„ж•°жҚ®еҜје…Ҙи§ЈеҶіж–№жЎҲгҖӮеҸӘжңүиҝҷж ·пјҢз”ЁжҲ·жүҚиғҪзңҹжӯЈд»Һж•°жҚ®еҜје…Ҙзҡ„з№ҒзҗҗиҝҮзЁӢдёӯи§Јж”ҫеҮәжқҘпјҢдё“жіЁдәҺжӣҙжңүд»·еҖјзҡ„ж•°жҚ®еҲҶжһҗе’ҢеҶізӯ–е·ҘдҪңгҖӮ
з»јдёҠжүҖиҝ°пјҢExcelеҜје…Ҙж•°жҚ®еҗҺеӯ—ж®өеҗҚеҸҳдёәвҖңF1вҖқгҖҒвҖңF2вҖқзӯүй»ҳи®ӨеҗҚз§°зҡ„й—®йўҳпјҢиҷҪ然зңӢдјјз®ҖеҚ•пјҢеҚҙж¶үеҸҠж•°жҚ®еҜје…ҘжңәеҲ¶гҖҒеӯ—ж®өжҳ е°„йҖ»иҫ‘д»ҘеҸҠExcelзҡ„ж•°жҚ®еӨ„зҗҶжһ¶жһ„зӯүеӨҡдёӘжҠҖжңҜеұӮйқўгҖӮйҖҡиҝҮзҗҶи§ЈиҝҷдёҖзҺ°иұЎиғҢеҗҺзҡ„еҺҹеӣ пјҢ并йҮҮз”ЁеҗҲйҖӮзҡ„и§ЈеҶіж–№жЎҲпјҢз”ЁжҲ·еҸҜд»Ҙжӣҙй«ҳж•Ҳең°еӨ„зҗҶж•°жҚ®еҜје…Ҙй—®йўҳгҖӮеҗҢж—¶пјҢиҝҷдёҖй—®йўҳд№ҹеҸҚжҳ дәҶж•°жҚ®еҜје…Ҙе·Ҙе…·еңЁз”ЁжҲ·дҪ“йӘҢе’ҢеҠҹиғҪи®ҫи®ЎдёҠзҡ„ж”№иҝӣз©әй—ҙпјҢжңӘжқҘзҡ„е·Ҙе…·ејҖеҸ‘йңҖиҰҒжӣҙеҠ жіЁйҮҚз”ЁжҲ·йңҖжұӮе’ҢиЎҢдёҡи¶ӢеҠҝпјҢдёәз”ЁжҲ·жҸҗдҫӣжӣҙеҘҪзҡ„ж•°жҚ®еҜје…ҘдҪ“йӘҢгҖӮ